· Philipp Leser
Kaggle Competition
Anomalie-Detektion für das Übertragungsnetz, oder "how to win a Kaggle competition without even (really) trying"

Für mich ist das europäische Übertragungsnetz ein technisches Wunderwerk, denn wenn man mal genauer darüber nachdenkt, ist es fast schon überraschend, wie fehlerfrei alles funktioniert.
Im Rahmen der Abschlussveranstaltung zur “AI Service Grid Stability Challenge” hat TransnetBW GmbH zu einem Termin vor Ort eingeladen.
Mehrere “Marktstände” mit interessanten Problemen und beeindruckenden Lösungen. Eine angenehme “can do“ Einstellung im Angesicht neuer Herausforderungen und Möglichkeiten. Da die Modelle, Szenarien und Hochrechnungen für einen Blackout eher gruselig sind ( siehe zum Beispiel hier ), beruhigt mich das sehr 😊.
An dieser Stelle wollten wir den Veranstaltern noch einmal danken. Danke an Alexander Werling, Dr. Matthias Ulrich Bohner, Andreas Semmig, Michael Salzinger, Simon Remppis und Dr.-Ing. Dominik Schlipf für die Organisation, nette Gespräche und informative Vorträge. Natürlich auch ein Dank an das Fraunhofer IEE und hessian.AI , ohne die der eigentliche Wettbewerb auf Kaggle nicht stattgefunden hätte.
Die Kaggle Competition
Die Competition AI Serving Grid Stability hatte sich zum Ziel gesetzt, die Verwendung von Machine Learning (oder “KI”) zur Detektion von Anomalien in der Energiewirtschaft voranzutreiben. Hierzu hat man mithilfe der Forscher vom Fraunhofer Institut und dem Team von TransnetBW einen Datensatz vorbereitet und zur Verfügung gestellt.
Dieser Datensatz war für die Data Cybernetics hochinteressant und der eigentliche Grund, warum wir uns bei der Competition angemeldet hatten. Der Datensatz kommt aus dem PICASSO System ( hier die Dokumentation auf entso-e ).
PICASSO ist eine der stillen Erfolgsgeschichten europäischer Kooperation. Es handelt sich dabei um eine von vielen Integrationen der europäischen Regelenergiemärkte, im Speziellen geht es um den Austausch von aFRR (automated Frequency Restoration Reserve oder sekundäre Regelleistung). Die Vorgehensweise ist exakt hier dokumentiert. Grob zusammengefasst: Alle 4 Sekunden wird das gesamte europäische Stromnetz optimiert. Gegeben der Übertragungskapazitäten werden im ersten Schritt die Imbalancen der einzelnen Regelzonen gegeneinander ausgeglichen. Zum Ausgleich der verbliebenen Imbalancen wird dann im zweiten Schritt an den europäischen Märkten Regelenergie beschafft (wieder gegeben der noch verfügbaren Übertragungskapazitäten). Dabei wird versucht, das gesamteuropäische sozioökonomische Optimum zu erreichen. Mir ist schleierhaft, warum dieses System in den Medien und Politik nicht mehr beworben wird.
Für uns war der Wettbewerb interessant, da wir:
- primär in der Energiebranche und an Energiethemen arbeiten.
- insbesondere auch schon viel mit “Ancillary Services” zu tun hatten (FCR, aFRR, mFRR, BESS Optimierung…).
- viel Erfahrung mit Systemen zur Anomaliedetektion in Echtzeit auf multiplen (oder multivariaten) Zeitreihen haben.
Wir kennen das Thema Ancillary Services primär aus der Sicht der Marktteilnehmer, die diese Services anbieten. Die Sicht des TSO (Transmission Service Operator) auf dieses Problem ist aber enorm wichtig, um die Ancillary Service-Märkte und Systeme zu verstehen. Auch wenn wir gut mit den Märkten für Regelleistung und Regelenergie vertraut sind, gibt es immer noch mehrere Details im PICASSO System, die wir nicht verstanden haben. Von dem spannenden Feld des optimalen Betriebs des Übertragungsnetzes ganz zu schweigen.
Wir hatten also genügend Gründe, uns tiefer mit dem Datensatz zu beschäftigen.
Der Datensatz besteht aus Zeitreihen mit Messungen von 13 unterschiedlichen Komponenten des PICASSO Systems. Diese Daten liegen jeweils für ein halbes Jahr und zwei Regelzonen vor.
Wie bei Kaggle Competitions üblich, ist das Datenset in ein “Train” und ein “Test” Set aufgeteilt. Der “Train” Datensatz kann genutzt werden, um die “KI” Modelle zu trainieren. Daraufhin müssen die Wettbewerber ihre Modelle nutzen, um Vorhersagen auf dem “Test” Datensatz zu machen. Diese Prognosen werden dann auf der Kaggle Plattform hochgeladen und nach Ende des Wettbewerbs ausgewertet. Die endgültigen Ergebnisse werden dann auf dem private leaderboard veröffentlicht, in der Regel gibt es auch ein public leaderboard . Hier können Teilnehmer die Ergebnisse ihrer hochgeladenen Lösungen begutachten, die auf einem Bruchteil des Testsets ausgewertet wurden. Daher ist natürlich nur das private leaderboard für die Bewertung des Wettbewerbs relevant. Im Machine Learning ist es generell eine Todsünde, seine Modelle zu sehr darauf zu optimieren. Diese Art, Wettbewerbe auszuwerten, treibt manchmal seltsame Blüten und führt leider häufig zu praktisch nicht einsetzbaren Lösungen.
Generell entsprach der Datensatz dem, was wir es aus vielen unterschiedlichen Anomalie-Detektion Problemstellungen in der Praxis kennen. Auch das “Train” Set beinhaltet Anomalien, diese sind aber nicht als solche gekennzeichnet.
Wir waren hoch motiviert. Von Anfang an war uns klar, dass wir nicht unbedingt den Wettbewerb gewinnen wollen, sondern etwas bauen wollen, das TransnetBW beim Betrieb der PICASSO Plattform helfen könnte. Unsere Ansichten, was ein System zur Anomaliedetektion alles benötigt, um in der Praxis tatsächlich Verwendung zu finden, sind hier nachzulesen.
PICASSO ist ein System zur Regelung und Optimierung. Die Inputs dieses Systems und Schocks mögen zufällig sein, die Kommunikationskanäle mögen verrauscht sein, aber das Regelsystem selbst ist in erster Linie deterministisch.
Unser Ziel war es:
- möglichst viel Domänenwissen aufzubauen und dieses Wissen in deterministischen Regeln abzubilden.
- einen digital-twin des Regelsystems zu bauen.
- diesen Twin dann nutzen, um das Verhalten des Systems zu prognostizieren.
- diese Prognosen dann mit Machine Learning zu ergänzen.
- mithilfe von Conformal Prediction Aussagen über die Wahrscheinlichkeit des gemessenen Ergebnisses zu machen.
Dies sollte zu einem System führen, das nicht nur Anomalie-Detektion ermöglicht, sondern auch Decision-Support und Root-Cause Analyse erlaubt.
Uns wurde leider schnell ersichtlich, dass uns für den oben aufgeführten Ansatz benötigte Daten fehlen (insbesondere die Grid-Frequency). Eine weitere Inspektion der Daten machte offensichtlich, dass es nicht viel zu optimieren gab. Etwas enttäuscht beschlossen wir, wenigstens einen einfachen Ansatz einzureichen. Hierzu griffen wir auf eine von uns häufig verwendete Methode zurück.
Winning Solution
Zuerst gilt es anzumerken: offensichtlich war es gefährlich, zu sehr auf den einzigen Datensatz mit markierten Anomalien (das public leaderboard) zu optimieren. In diesem Szenario spielt Glück eine große Rolle! Fooled by Randomness ist ein wertvolles Buch, dessen wesentliche Message auch für Kaggle Competitions gilt. Es ist schwer, sich einzugestehen, dass man nicht viel machen kann und bei “man” meine ich “niemand”. Egal, wie toll das “KI-Verfahren” ist, das man plant einzusetzen, die Daten geben einfach nicht mehr her! Es benötigt viel Erfahrung, speziell schlechte Erfahrungen, dem Drang zur weiteren Optimierung zu widerstehen und nicht in die “over fitting” Falle zu treten. Das “public leaderboard” sind nur 30 % des Testdatensatzes! Zusätzlich handelt es sich hier auch noch um Anomalien, auch wenn diese natürlich im Test-Datensatz überproportional vertreten sind, sind sie definitionsgemäß immer noch selten. Wer das mal ein wenig simuliert (30 %-Stichprobe aus einem Datensatz mit Anomalien ziehen), muss zu der bitteren Erkenntnis kommen: Die Ergebnisse des public leaderboards tragen nahezu keine Information! Ich habe das public leaderboard daher komplett ignoriert.
Wir haben den ersten Platz den folgenden Umständen zu verdanken:
- kein overfit auf einem nicht informativen Datensatz → deshalb wurden wir nicht nach unten durchgereicht.
- einen robusten Ansatz, der es schafft, die Daten aus dem Train Set zu heben.
- nur wenige Wettbewerber.
- und natürlich eine gute Portion Glück.
Trotzdem haben wir erneut feststellen können, dass unsere Art, Anomalie-Detektionsprobleme anzugehen, auch hier gut funktioniert hat.
Die Vorgehensweise ist relativ simpel:
- Wir nutzen unser Domänenwissen und explorative Datenanalyse, um den Trainingsdatensatz mit statischen Regeln aggressiv zu bereinigen. Wir haben fast 30 % der Tage weggeworfen!!
- Unser Ziel war es, ein System zu bauen, das den normalen Zustand des Systems prognostizieren kann!
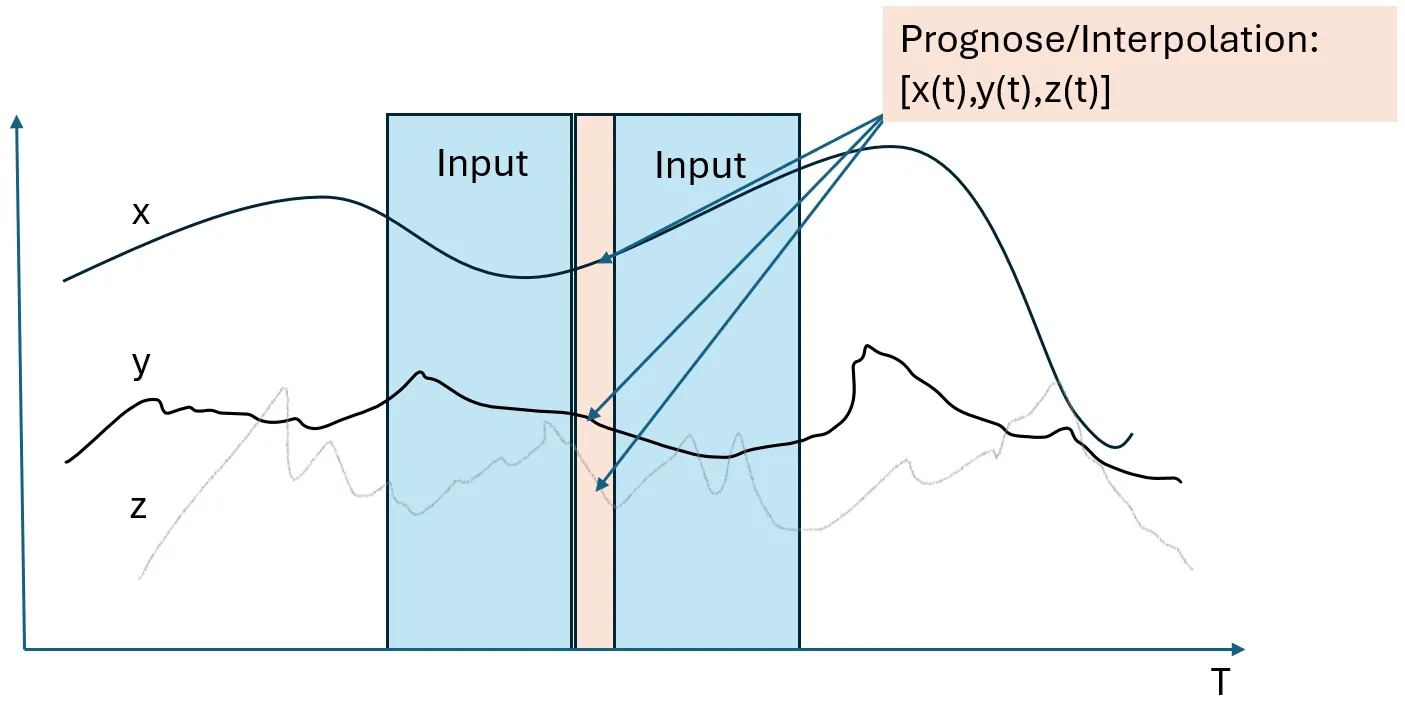
- Hierzu verwenden wir 12 Zeitschritte in der Vergangenheit und 12 Zeitschritte in der Zukunft, um den aktuellen Zustand zu prognostizieren (oder besser zu interpolieren).
- Wenn dieses System Fehler akkumuliert, haben wir eine Anomalie. Aus dem durch einfache Regeln bereinigten Trainingsdatensatz wird hierzu ein Teil der Daten für die Kalibrierung der Fehlersumme verwendet.
Dieser “Imputation” Ansatz versucht den Wert aller 13 Zeitreihen gleichzeitig zu prognostizieren, dies ermöglicht sowohl zeitliche Abhängigkeiten als auch Abhängigkeiten zwischen Variablen zu erlernen. Da wir Daten aus der Zukunft verwenden, ist der Ansatz in der Regel in der Lage, relativ exakt zu interpolieren. Eine Einschränkung ist, dass man etwas abwarten muss, bis man die nächste Prognose bekommt. In diesem speziellen Fall 12 × 4 = 48 Sekunden. Es wurde uns aber von TransnetBW zugesichert, dass dies eine absolut akzeptable Latenz ist. Es ging TransentBW um die Erkennung von Anomalien innerhalb von weniger Minuten.
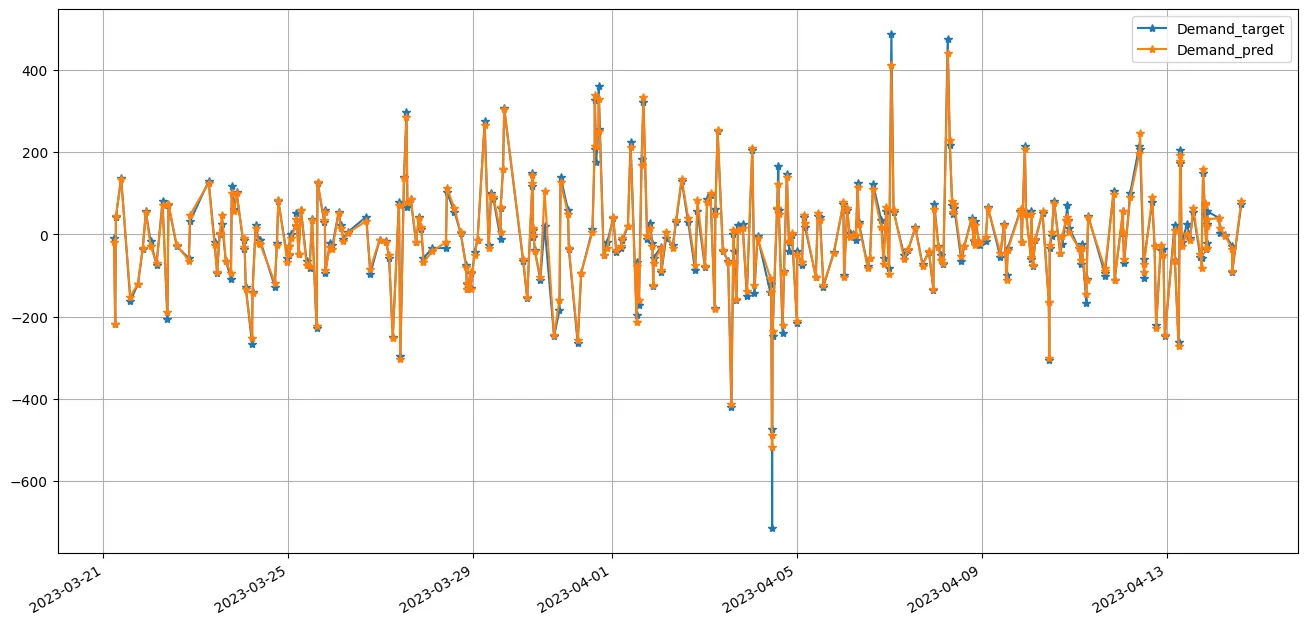
Das hier verwendete Machine Learning Verfahren ist Catboost, spielt aber IMO keine Rolle. Wir haben hier kein Forecast Problem. Es geht darum, die Abhängigkeit zwischen den Komponenten zu erlernen und ein gutes Verständnis über die Fehler der Interpolation zu bekommen und nicht zufällige Änderungen in der nachgefragten aFRR Menge zu prognostizieren. Die Prognosen im normalen Zustand des Systems sind (ohne ernsthafte Hyperparameter-Optimierung) entsprechend gut.:
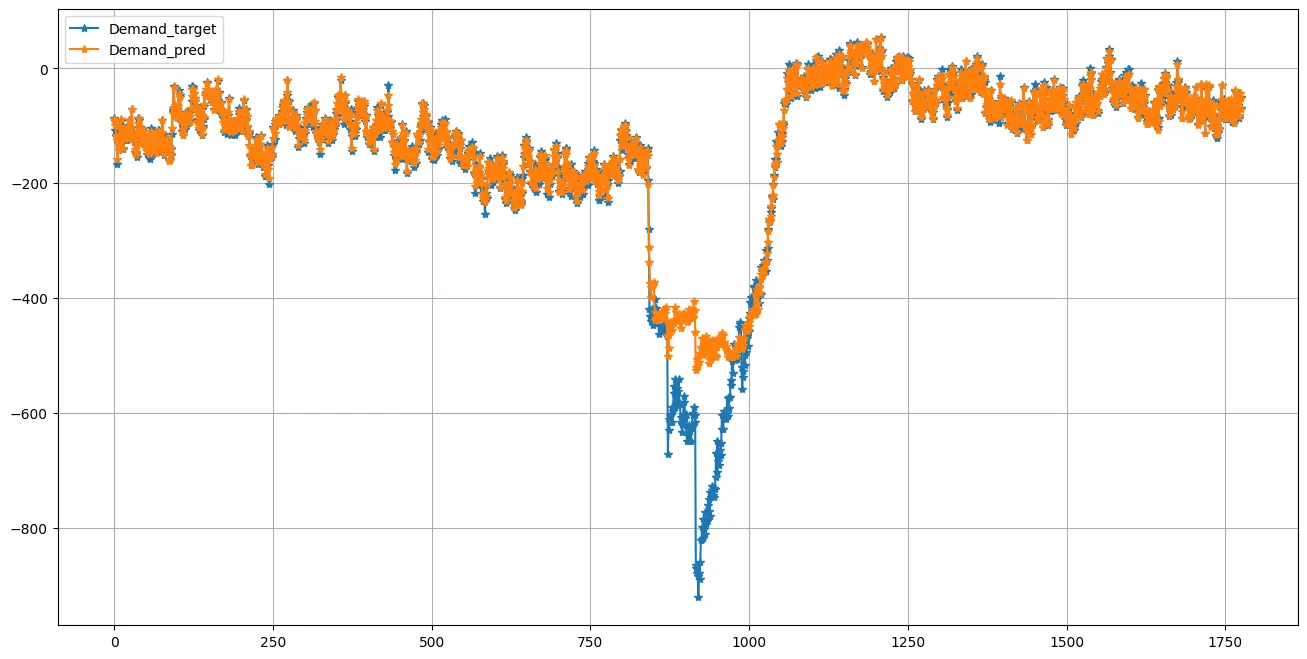
Bei persistenten Anomalien sammelt das Prognosesystem schnell Fehler auf, die wir so im Trainingsset nicht beobachtet haben:
Zusammenfassung
Leider konnten wir unsere Idee, eines praktisch nutzbaren Systems zur Detektion von Anomalien im PICASSO System zu entwickeln, nicht umsetzen. Dazu fehlten wichtige Daten. Es war aber schön, erneut festzustellen, dass unsere grundsätzliche Herangehensweise, Anomalien zu detektieren, befriedigend funktioniert. Wir haben auch einige Lücken in unserem Verständnis zur Funktionsweise des PICASSO Systems schließen können und auch der Termin vor Ort in Wendlingen bei TransetBW war sehr aufschlussreich. Eventuell ergibt sich in Zukunft eine Chance, TransnetBW (oder andere TSOs) bei dieser oder ähnlichen Fragestellungen zu unterstützen.